This is a challenging task that is usually solved using inefficient approach.
Large software projects are usually heterogenous and there maybe some anti-patterns and design patterns, that are essential to understand the project well.
If starting to do just one task, and cumulating the understanding task by task, you are biased based on the selection of the task, and based on the open issues there are right now in the project. You might miss the core essence of the system, or just misunderstand it totally. This is
Softagram approach to achieving understanding and becoming productive developer in the project:
- Pick a tool that is able to analyze the source code structure, history and the dependencies, and that supports the programming language used in the project (easy task, there aren’t that many, and you can write your own scripts too)
- Run the analysis (usually very fast) to produce the analysis information
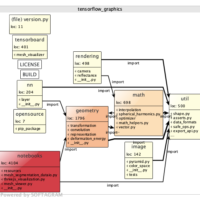
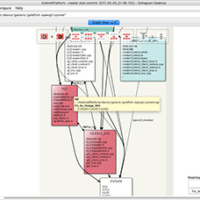
- Browse the analysis model
- Use heatmaps to see where are the hotspot files (constantly changing, commit_count_365 high, complex places and all the time demanding the developer attention)
- See what are the biggest places (files with most code, use loc heatmap)
- See what places have stopped changing (days_since_modified heatmap)
- See if the directory hierarchy matches with the dependency network
- This can be found out by checking if the directory level dependency views show clear good-looking layered graphs and the dependencies do not connect everything to everything.
- If matches, go right to the top level directories and browse the dependencies between subdirectories to get the overall architecture understanding. This helps you to understand the big components and what are their relationships to each other.
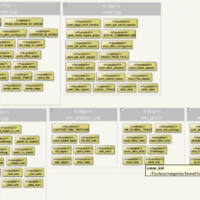
- If it does not match, flatten the directory hierarchy away (Flatten Model at High Level) from the model and utilise the dependency clusters instead. Flat model of classes and their dependencies shows you the co-dependent classes in separate clusters when using visualization algorithms.
- Do some queries for the keywords you have found essential so far. E.g. certain logical functionality might be scattered all over the code base but when you make searches found it from different contexts in the codebase you start to deeply understand the project, how it has been structured (or evolved with structuring intent).
- For each major component of the system, look at its inbound view to see what uses it and why it exists.
- For each major component of the system, look at its outbound view to see if there is trouble ahead with that by checking if some of those has huge number of outgoing dependencies. The more outgoing dependencies there are, the more complexity and responsibilities it has. It is good to split them up if you get a refactoring task to improve the structure.
- Run checks for cyclical dependencies on several levels (you can also spot that quite easily visually just to see if the default layout shows any upward dependencies) to see if the codebase has been written using layered approach, and discuss about that with the team. This understanding is critical for you when doing new features.
The above process (steps 2–8) usually takes 2–4 hours work in medium codebases. The good side is that it is language agnostic. The models are generic for all languages. For example, a recent software audit for 150 000 LOC after spending 3 hours we were already looking at these views with the customer person and making useful observations on the system and getting the idea how stuff works there.
The gathered understanding will let you reach high productivity and do less errors and help you to maintain the system integrity.
The Softagram has free trial in cloud. You can also contact us via website chat for piloting the on-premises installed system using our VirtualBox image.
Softagram Desktop is just for doing the “Browse the analysis model” phase above, and is available for download at
softagram.com/desktop